Temporal Expressions Extraction and Normalization for Cultural Heritage Archive Using Word Vector Representation
Watchira Buranasing, Thepchai.supnithi, Pattaraporn.meeklai,
Phattarapol Jantarasena, Petchwadee Pattarathananan
National Electronics and Computer Technology Center
Thailand Science Park, Klong Luang, Pathumthani 12120, Thailand
{watchira.buranasing, thepchai.supnithi, pattaraporn.meeklai}@nectec.or.th
{petchwadee.pat, phattarapol.jan}@ncr.nstda.or.th
Abstract
Cultural Heritage refers to the legacy of the group of people. There are tangible cultural heritage and the intangible cultural heritage assets. The digital cultural heritage has become an issue to preserve the cultural heritage material as the assets. One of the important parts of the cultural heritage or historical archive is the time for identifying and understanding of the event happened. This paper introduces an approach for extracting temporal expression and normalizing values from various data sources. We design a model for extracting temporal expression based on semantic extraction rules and word vector representation and normalize values from various time format to the same format. We design a model for extracting the relationship between the event and temporal expression. The experimental results show the accuracy of time expression extraction for the normalized form date/time is 0.90 and the accuracy of relation extraction with time expression for the normalized form date/time is 0.85.
Keywords-Temporal expression, Cultural heritage archive, digital preservation, word vector
1. Introduction
Cultural Heritage [1][2] refers to the legacy of the group of people. There are tangible and intangible cultural heritage assets, that can be defined as Tangible cultural heritage assets are the physical items that can be perceived by the sense of touch include buildings, museums, monuments, and historical sites. Intangible cultural heritage assets are social customs and wealth of knowledge that are held and shared by people include traditions, music, and dancing. The digital cultural heritage has become an issue to preserve the cultural heritage material as the assets.
One of the important parts of the cultural heritage or historical archive is the time for identifying and understanding of the event happened. Two types of temporal information related to the events. The first is the temporal expression, also called Timex, it is the sequence of words, that show when something happened and the second is the temporal relation, that shows the relation between events and time. The temporal information extraction from raw text is the fundamental task of natural language processing (NLP) and deep learning. It is the key for many application such as question and answering (QA), information retrieval and information extraction. The problem of time identifying is there is a lot of data format of time that show both explicit and implicit forms in temporal expressions, for example:
1. วัดบ้านนาคำ เริ่มก่อตั้ง ปี พ.ศ. 2492 ถึง พ.ศ. 2499 (Bannakam is built in 2492-2499 B.E.)
2. พระเจดีย์บุษบา วัดสระแก้ว สร้างขึ้นเมื่อร้อยปีก่อน (Busaba pagoda at Srakeaw temple is built in on hundred years ago.)
3. วัดหนองปลิง ตั้งขึ้นเมื่อ พ.ศ. ๒๕๒๖ (NongPling Temple is built in 2526 B.E.)
The idea of the temporal extraction works on the information of each article from cultural heritage archive. There are various techniques for temporal extraction and normalization. Angel X. Chang and Christopher D. Manning [3] present SUTIME, a temporal tagger for recognizing and normalizing temporal expressions in English. It is a rule-based system designed for extensibility. Prateek Jindal and Dan Rothn [4] design the features for event extraction. Their features are to construct a clinical descriptor for any concept using medical ontologies. They develop an inference strategy which ensures that the attributes of related events are consistent with one another. They apply the HeidelTime system for use in clinical narratives and develop several rules which complement HeidelTime. Nils Reimers et al. present [5] a method to automatically anchor events in time. They create a decision tree and apply neural network based classifiers for the nodes. They use this tree to incrementally infer in a stepwise manner, at which time frame an event happened. They evaluate the approach on the TimeBank-EventTime Corpus. Naushad UzZaman and James F. Allen [6] present a system for extracting event, event features, temporal expression and normalizing values from raw text. Their system is a combination of deep semantic parsing with extraction rules, Markov Logic Network classifiers and Conditional Random Field classifiers. They evaluate the system on the TimeBank corpus.
This paper introduces an approach for
extracting temporal expression and normalizing values from various data
sources. The main challenges of work could be summarized as:
- We design a model for extracting temporal expression based on semantic extraction rules and word vector representation and normalize values from various time format to the same format.
- We design a model for extracting the relationship between the event and temporal expression.
The remaining of the paper is organized as follows. Section 2 gives an overview of the model. Section 3 shows the experimental results and Section 4 shows the conclusion and discussion of future directions.
2. System Overview
2.1. System Design
For this approach, Figure 1. Show the methods and components of the temporal expression extraction and normalization.
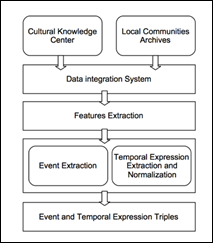
Fig. 1 The components of the temporal expression extraction and normalization system.
We integrate cultural heritage information from cultural knowledge center (www.m-culture.in.th) and local community archives (www.anurak.in.th). We extract word feature such as POS and position of words. We extract event and temporal expression using the combination of the rule base and word vector representation. We normalize the value of the temporal expression from various time format to the same format. We discovered the relation between the event and temporal expression.
2.2 Temporal Expressions
The temporal expression is the sequence of words that shows when something happened or how long did it happen. The temporal expression can be explicit such as calendar date, time and inexplicit such as “almost 100 years”. The temporal expression will annotate with the following items:
- Lexical Triggers: The temporal expression must use at least one mark such as calendar date, era, semester, January.
- Type: The temporal expression needs to be assigned a type such as Date, Time, Duration and Set.
- Value: The value of temporal expression.
We focus on four form of time expression: Normalized form date/time (2018/08/10), Modifier form (80 years ago), Duration form (2018/09/10-2018/09/13) and Frequency form (every three years).
2.3 Temporal Expression Extraction
Word embedding have become an essential part of deep learning based on natural language processing systems. Word embeddings represent the semantics of a word in a continuous vector space, where semantically similar words are mapped to nearby points. This paper, we use Skip-gram model [7][8] for predicting the surrounding words in the sentence focus on the event and temporal expression. The sequence of training words are w1, w2,… , wT. The purpose of the model is to maximize the average log probability.
![]()
where c is the size of training context. The Skip-gram formulation defines p(wt+j |wt) using the softmax function:
![]()
where vw and v ′ w are the “input” and the “output” vector representations of w, and W is the number of words in the vocabulary.
The representations of time after reduction to two dimensions that shows the clusters of the semantically related words. Fig 2. shows the example of results for temporal expression represents by word vector.
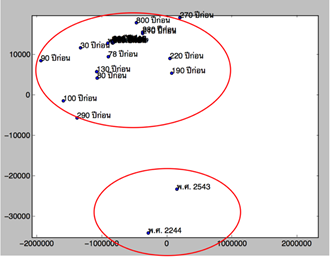
Fig.2 The temporal expression represented by word vector.
Besides the normalized form such as the month and the year, there are the interesting form to observe, for example, the modifier form e.g., 100 years ago), the duration form e.g., 2469 B.E. - 2475 B.E. Table 1 shows the closest words to a given term ordered by distance.
Table 1. The example of temporal expression form
|
Temporal Expression Form |
The value of temporal expression |
|
Normalized form date/time/era (Thai numeral/Arabic numeral) |
พ.ศ. ๒๔๐๐ (2400 B.E.), พุทธศักราช ๒๔๐๕ (2405 Buddhist era), พ.ศ. 2484 (2484 B.E.) |
|
Normalized form date/time/era (Text) |
รัตนโกสินทร์ศก (Rattanakosin era), จุลศักราช (Culāsakaraj era) |
|
Modifier Form (Thai numeral/Arabic numeral) |
100 ปีก่อน (100 years ago), 200 ปีที่ผ่านมา (200 years ago) |
|
Modifier Form (Text) |
หนึ่งร้อยปีก่อน (one hundred years ago), แปดสิบปีก่อน (eighty years ago) |
|
Duration Form |
พ.ศ. 2469 – พ.ศ. 2475 (2469 B.E.-2475 B.E.) |
|
Frequency Form (Thai lunar calendar) |
ขึ้น 15 ค่ำเดือน 6 (the fifteenth day of the waxing moon in the sixth month), แรม 8 ค่ำ เดือน 6 (the eight) |
2.4 Relation Extraction
We discover the relation between event and temporal expression by searching temporal expression from the results of time expression extraction. We use POS tagging for finding the subject and predicate, that related to temporal expression. Fig. 3 show the triple of relation.
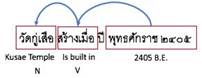
Fig. 3 the triple of relation extraction with temporal expression.
2.5 Temporal Expression Normalization
There are the year, month, date and the beginning and endpoint of each expression. Thai time have the various temporal expression, for example, มหาศักราช (Shalivahana era), จุลศักราช (Culāsakaraj era) and รัตนโกสินทร์ศก (Rattanakosin era). The original values of time also store. We convert Thai time expression into Buddhist era and Christian Eras by calculating as table 2.
Table 2. Temporal expression to normalized form
|
Temporal Expression |
Normalized Form/ Buddhist Eras |
Normalized Form/ Christian Eras |
|
|
Normalized form date/time/era |
|||
|
Shalivahana era |
Shalivahana era +621 |
(Shalivahana era +621)-543 |
|
|
Culāsakaraj era |
Culāsakaraj era +1181 |
(Culāsakaraj era +1181)-543 |
|
|
Rattanakosin era |
Rattanakosin era +2324 |
(Rattanakosin era +2324)-543 |
|
|
Buddhist era |
- |
Buddhist era-543 |
|
|
Modifier Form |
|||
|
Years ago |
» Recorded year - Number of the previous years |
» (Recorded year - Number of the previous years)-543 |
|
|
Duration Form |
|||
|
Duration |
- |
The beginning year-543 The end year -543 (depend of type of calendar era) |
|
|
Frequency Form |
|||
|
Thai lunar calendar |
- |
»Thai lunar year-543 (every year) |
|
We use the triple of relation extraction for visualization as the timeline, which shows the history of Thailand. Fig. 4 shows the example of timeline visualization in Normalized Form (Buddhist Eras).
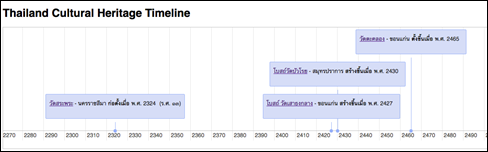
Fig. 4 The example of timeline visualization
3. Experimental Results
The data set for
our approach collected from two resources. The first is cultural knowledge
center of proposed Ministry of Culture. The second is cultural archives from
local community archives. We focus on title and description of the article. We
use 1,000 data for evaluation. The results are reported in Table 3.
Table 3. The experimental results
|
Temporal Expression Form |
Temporal expression |
RE with temporal expression |
||||
|
Precision |
Recall |
Accuracy |
Precision |
Recall |
Accuracy |
|
|
Normalized form date/time |
0.92 |
0.97 |
0.90 |
0.88 |
0.95 |
0.85 |
|
Modifier Form |
0.83 |
0.98 |
0.82 |
0.87 |
0.92 |
0.81 |
|
Duration Form |
0.91 |
0.95 |
0.88 |
0.85 |
0.92 |
0.80 |
|
Frequency Form |
0.76 |
0.86 |
0.69 |
0.83 |
0.86 |
0.75 |
4. Conclusion
This paper presents a methodology for extracting temporal expression and normalizing values from various data sources. We design a model for extracting temporal expression based on semantic extraction rules and word vector representation and normalize values from various time format to the same format. We design a model for extracting relationship between event and temporal expression. The experimental show the accuracy of time expression extraction for normalized form date/time is 0.90 and the accuracy of relation extraction with time expression for normalized form date/time is 0.85. In future work, we approach to extracting and normalizing the dependency temporal expression.
References
[1] Wikipedia : Culture, https://simple.wikipedia.org/wiki/Culture, 2015
[2] Culture, https://www.tamu.edu/faculty/choudhury/culture.html
[3] Angel X. Chang and Christopher D. Manning, “SUTIME: A Library for Recognizing and Normalizing Time Expressions”, The 8th International Conference on Language Resources and Evaluation (LREC), 2012.
[4] Prateek Jindal and Dan Roth, “Extraction of events and temporal expressions from clinical narratives”, Journal of Biomedical Informatics, Volume 46, Supplement, December 2013, Pages S13-S19
[5] Nils Reimers, Nazanin Dehghani and Iryna Gurevych, “Event Time Extraction with a Decision Tree of Neural Classifiers”, Transactions of the Association for Computational Linguistics, Volume 6, p.77-89, 2018
[6] Naushad Uzzaman and James F. Allen, “Extracting Events and Temporal Expressions from Text”, International Journal of Semantic ComputingVol. 04, No. 04, pp. 487-508, 2010
[7] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of
word representations in vector space, 2013
[8] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed representations of words and phrases and their compositionality. In C.J.C. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K.Q. Weinberger, editors, Advances in Neural Information Processing Systems 26, pages 3111–3119, 2013.